AV刮削终极解决方案-MDCNG
前情
之前已经通过 Autolady 实现了馒头订阅AV实现了自动化,这个时候我们结合的是 MetaTube 插件对emby里的学习资料进行的刮削。但是最近兴起了一个新的项目,体验下来刮削效果比较不错,就把我自己库里的emby已经全部洗版了一遍。实际用法和MP非常类似,相信用过的也会很快上手。
项目介绍
MDCNG 是一款开源的电影资料抓取与管理工具,尤其适合针对 AV 视频库的自动整理与美化。
-
智能刮削:支持30+刮削源,AI人脸识别裁剪,日亚高清海报下载
-
多种整理模式:硬链接、复制、移动、软链接、原地整理,适配各种场景
-
目录监控:自动检测新文件并刮削,支持性能和兼容两种模式
-
演员管理:联动Emby自动刮削演员信息和图片,内置演员数据库
-
手动整理:可视化文件管理,支持文件扫描、批量操作和任务管理
-
图片增强:4K/8K、影片类型水印标签,自定义位置和样式
-
智能翻译:支持OpenAI/Google等多引擎翻译,内置中文标题数据库
-
现代界面:Web管理界面,支持登录认证、主题切换、NSFW模式
技术栈
后端Rust,前端Nextjs,数据库SQLite。
功能介绍
🎬 视频刮削整理
支持5种整理模式,适配不同存储场景:
-
硬链接模式:节省空间,推荐本地使用
-
复制/移动模式:适合跨盘或网盘场景
-
软链接模式:创建链接到目标目录
-
原地整理模式:在原目录生成元数据
刮削流程:自动识别番号 → 多源抓取元数据 → 下载处理图片 → 整理文件 → 生成NFO
字幕支持:自动整理视频自带字幕文件,支持本地字幕库匹配
📁 目录监控
-
性能模式:实时监听文件变更,适合本地存储
-
兼容模式:定时检查更新,兼容网盘挂载
支持配置覆盖、文件过滤、自动清理等增强功能
👥 演员刮削
-
联动Emby服务端,自动刮削演员信息和图片
-
数据源:维基百科、minnano-av、graphis、gfriends
-
支持后台新入库演员自动刮削和批量管理
🖼️ 图片处理
-
AI裁剪:人脸识别智能定位裁剪海报
-
日亚高清:从Amazon日本搜索下载高清海报
-
水印功能:4K/8K、影片类型标签,多样式可选
-
独立工具:专门的海报裁剪工具
📊 任务管理与记录
-
任务持久化:完整的手动任务和监控刮削记录,支持状态追踪,便于维护和分析刮削成果
-
维护操作:支持批量重试、停止、删除等任务管理功能;支持指定番号或网页进行刮削
-
详情页面:美观的刮削详情页,包含画廊展示、完整元数据分析和实时日志推送;支持多来源数据手动精选修正
-
日志分析:详细的刮削日志和错误信息,便于问题排查
🌐 数据源支持
覆盖各类视频类型的30+刮削源,支持优先级配置、防反爬、自动重试
部署
镜像版本可以去本项目dockerhub页面查看
docker-compose
version: "2.1"services: mdc: image: mdcng/mdc:latest container_name: mdc environment: - PGID=1000 # 可选,设置组ID - PUID=1000 # 可选,设置用户ID - MDC_USERNAME=admin # 用户名密码可选,配置后开启登录鉴权模块 - MDC_PASSWORD=admin volumes: - ./data:/config # 配置目录,必须 - ./media:/media # AV媒体库,可映射多个 ports: - 9208:9208 restart: unless-stopped使用
访问 IP<9028> 进入 Web 进行管理
整理目录设置
首先来到设置,进行整理目录的设置,一般来说都是推荐硬链接模式。这样能把qb下载和媒体库这样分离开。如果之前已经整理过了,可以开移动(根据自己需求来吧,重新洗版一次)
元数据目录一般不需要,我更喜欢和视频保存在同一个文件夹下。
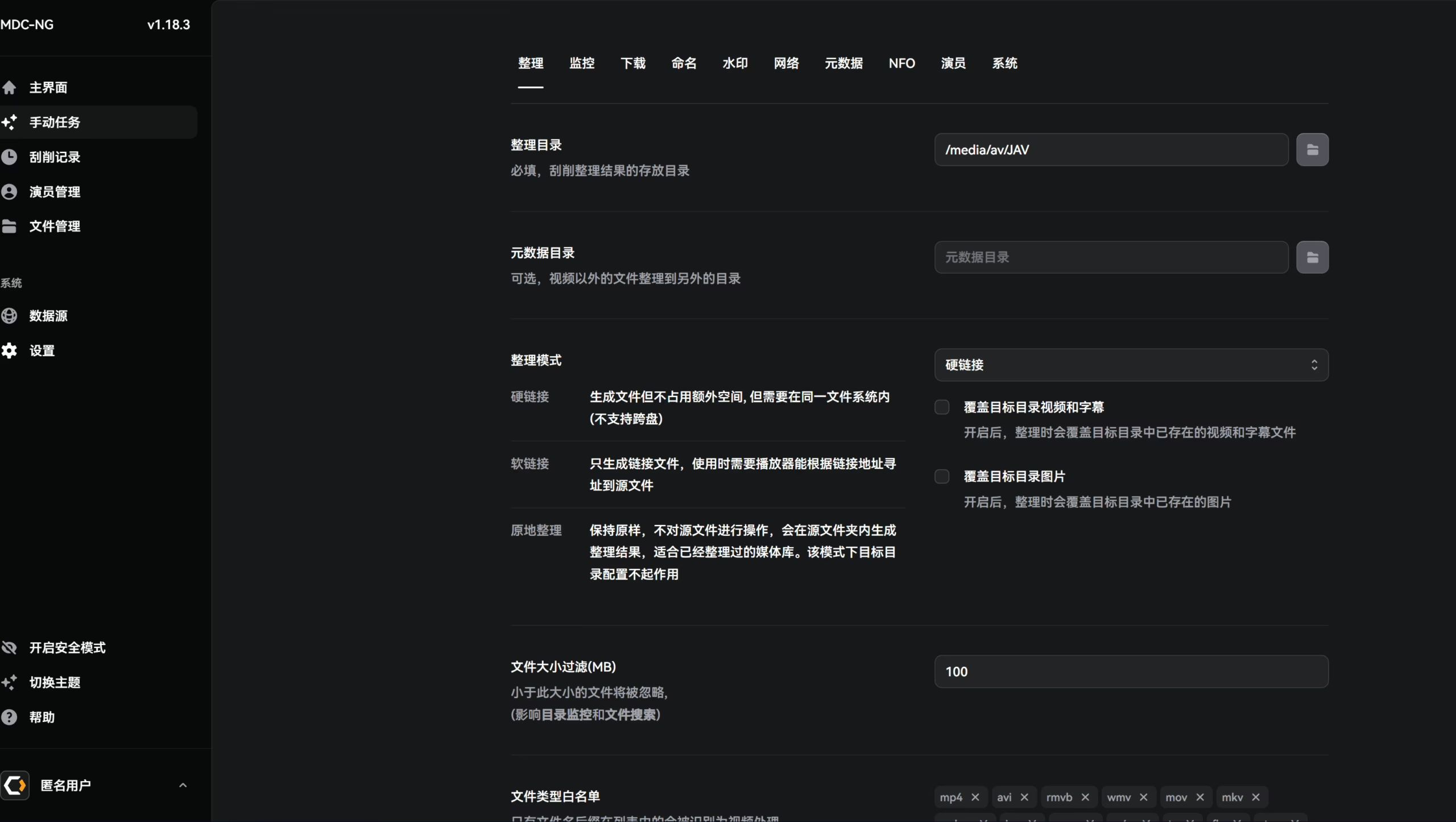
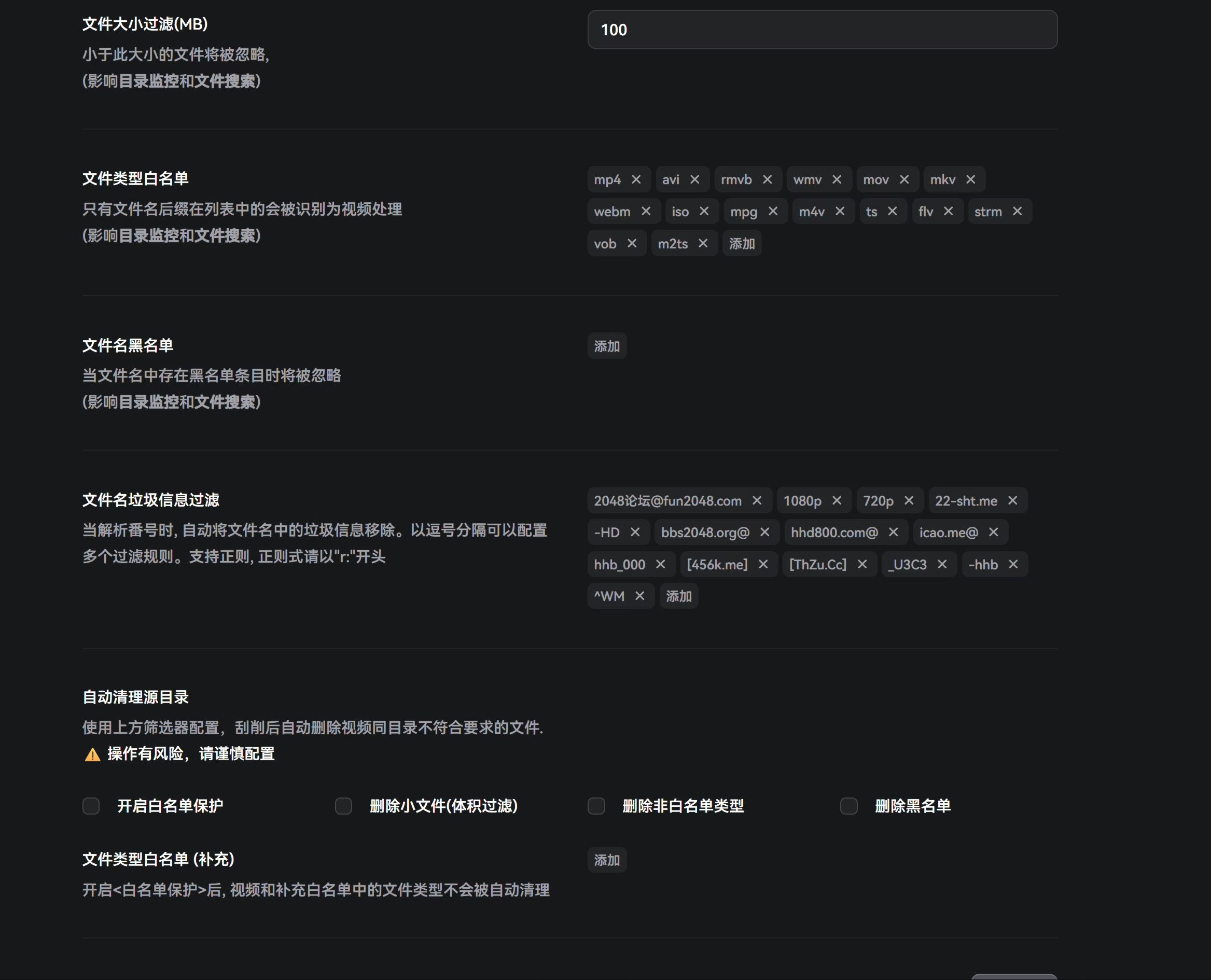
下面可以进行一些筛选词的过滤,因为做种的原因,有些AV种子里面会带广告,所以可以把里面的广告词给排除,使得最后的文件名整洁
数据源
非必要不修改,保持默认
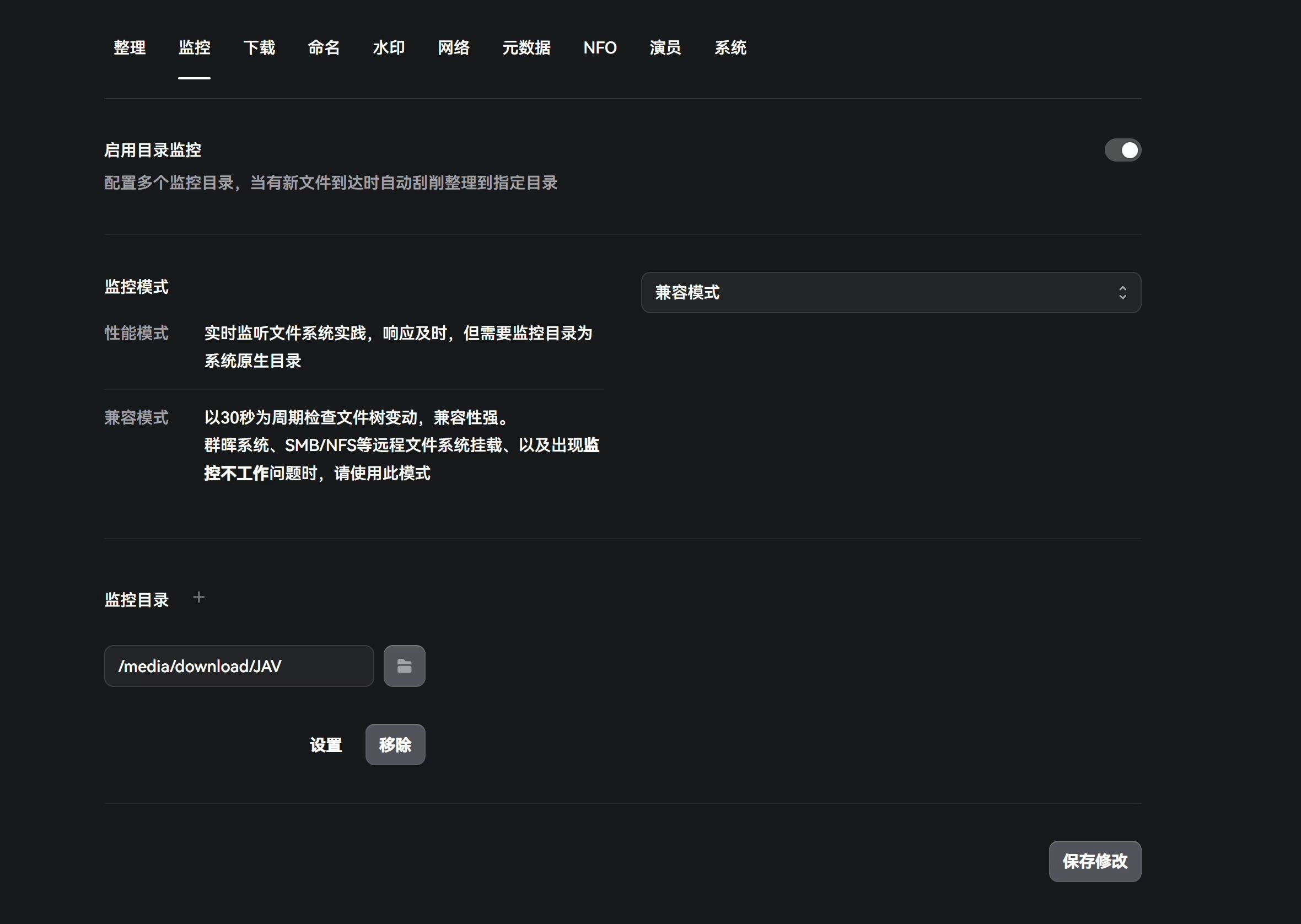
监控
这里就是对之前的qb下载av的位置进行监控,一般选兼容模式,我尝试过性能模式有些问题。可以尝试先选性能,看看检测是不是有问题,如果有再回到兼容模式。
性能模式实时监听文件系统实践,响应及时,但需要监控目录为系统原生目录
兼容模式以30秒为周期检查文件树变动,兼容性强。群晖系统、SMB/NFS等远程文件系统挂载、以及出现监控不工作问题时,请使用此模式
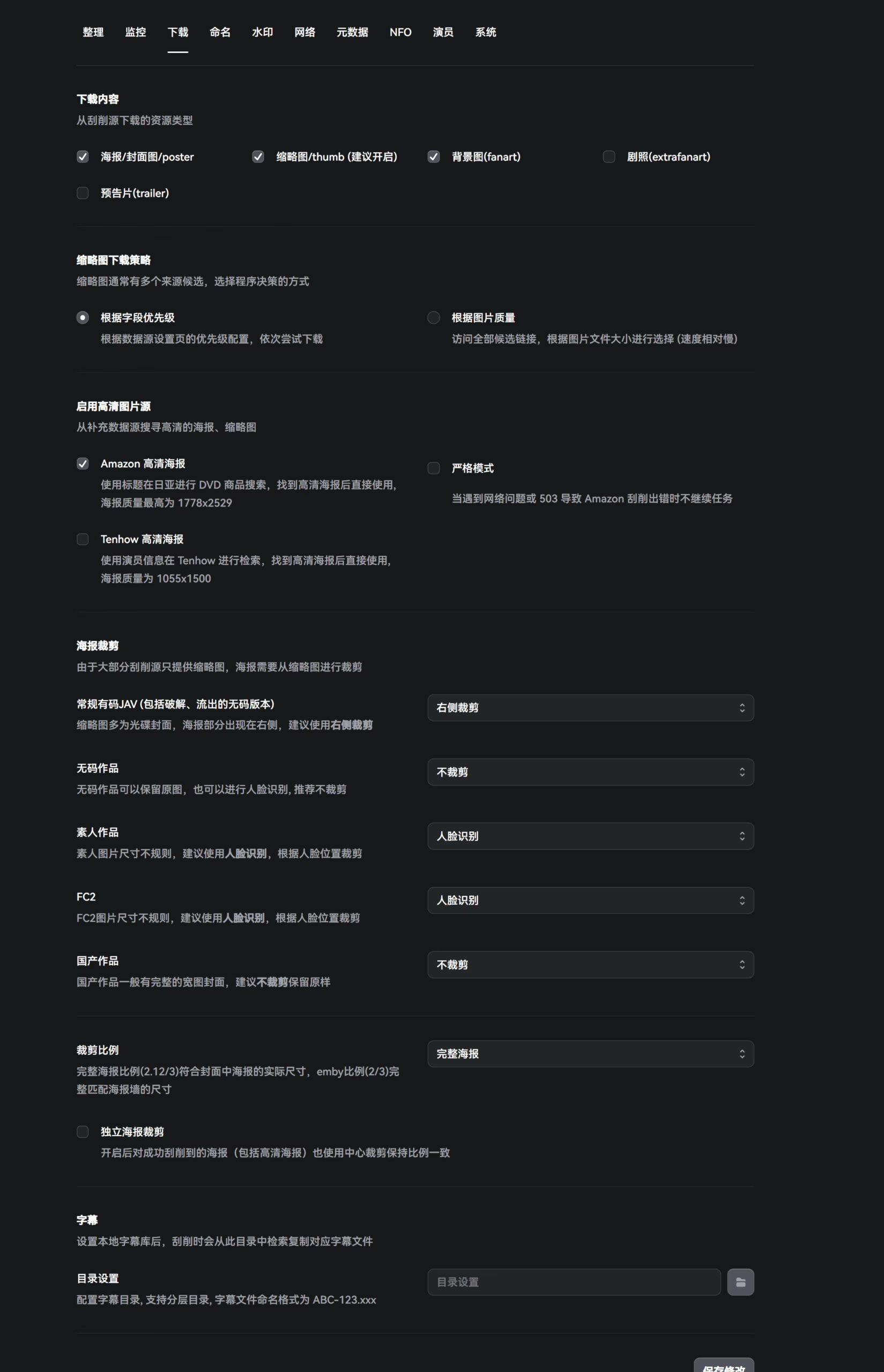
下载
这里是设置的nfo和那些海报墙,一般的话默认即可,不用特意去变动。
由于AV的特殊性,大部分中文其实都是内封好的,没必要设置字幕目录,起码我是不设置的。
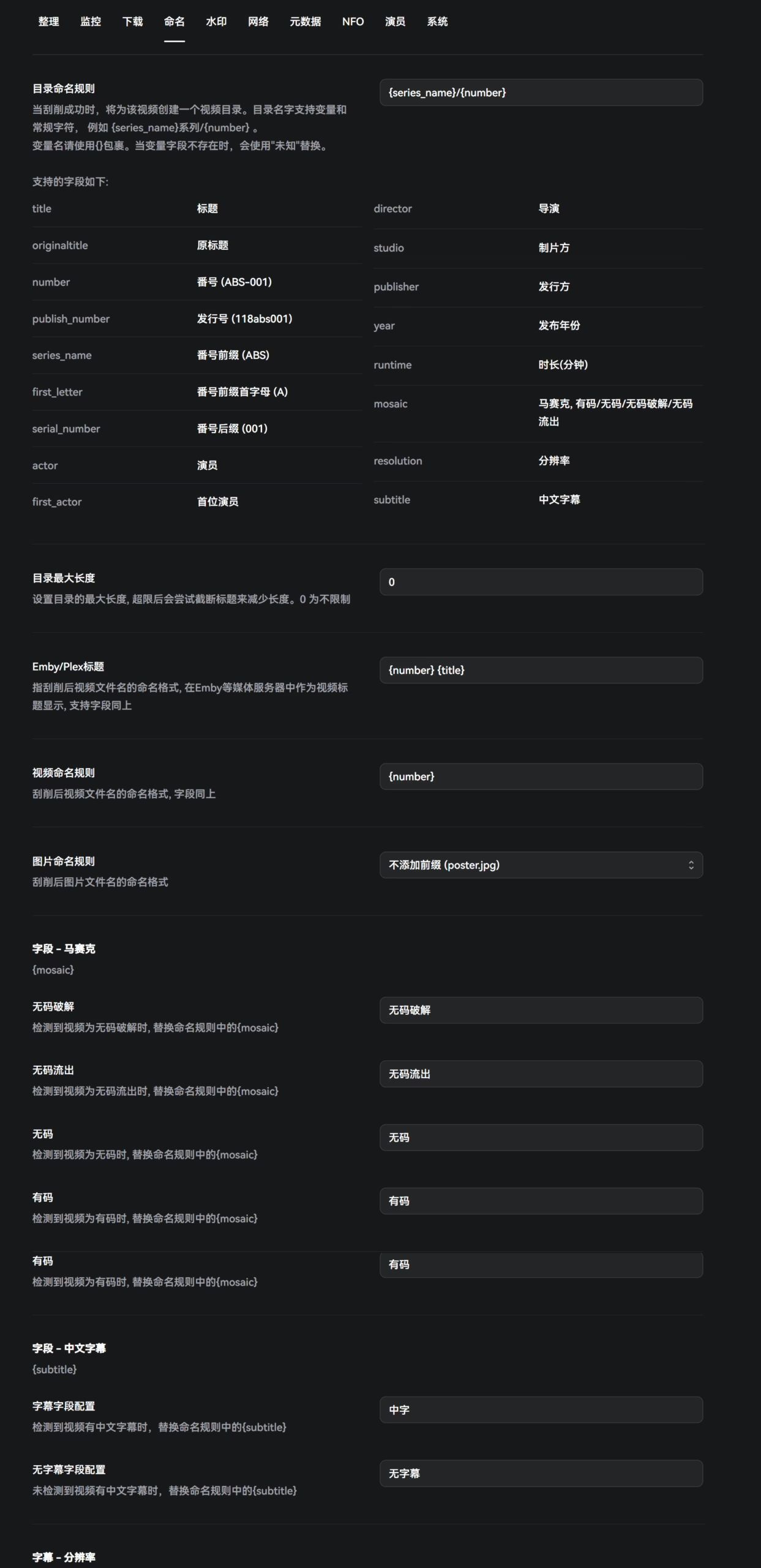
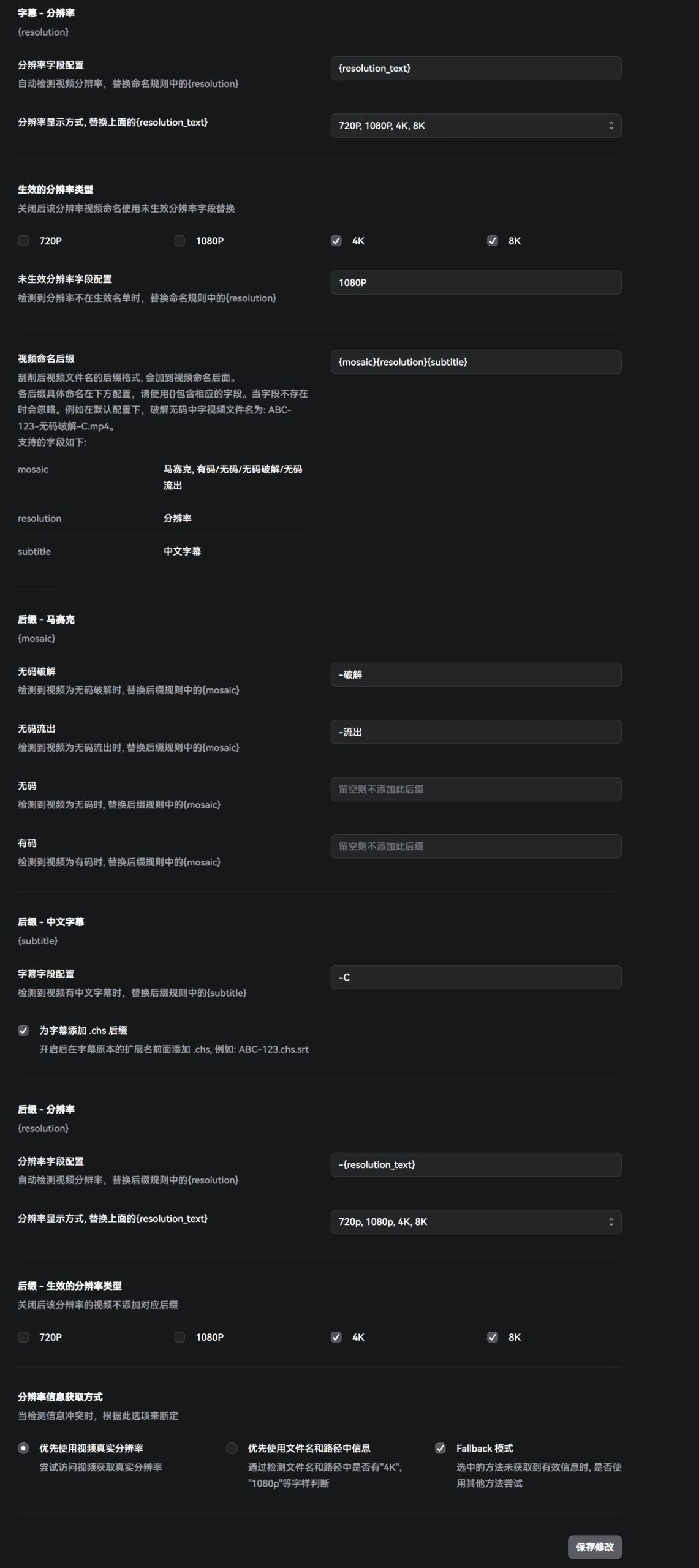
命名
这里是最关键的,设计到最后AV媒体库的命名。但是作者这个给的相当的清楚明白,每个参数都给了详细的解释。我由于不是很喜欢带女优的名字,因此我的命名都会剔除掉女优相关的。
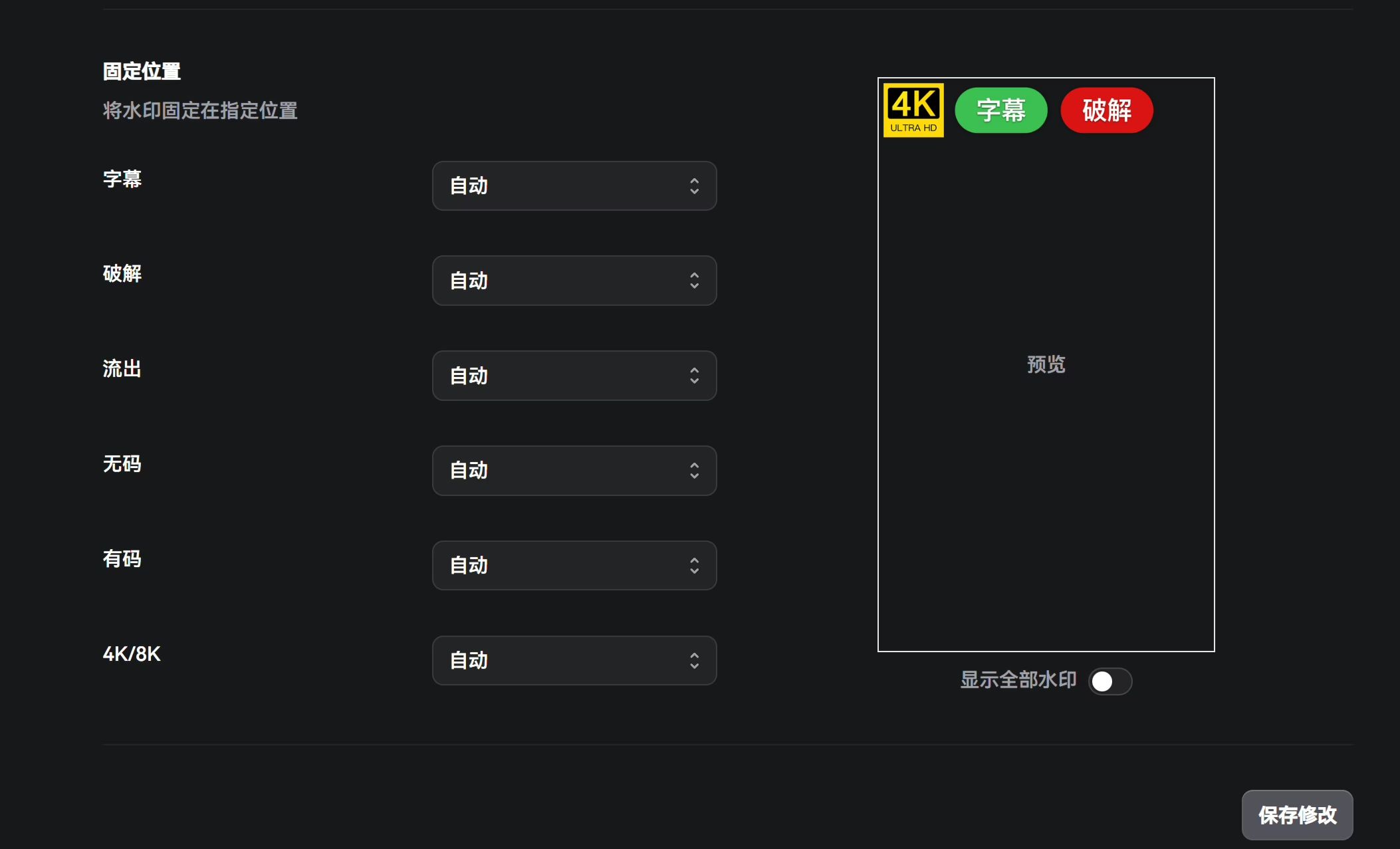
水印
这个其实没啥好设置的,我觉得作者默认的审美不错,因此直接默认了。
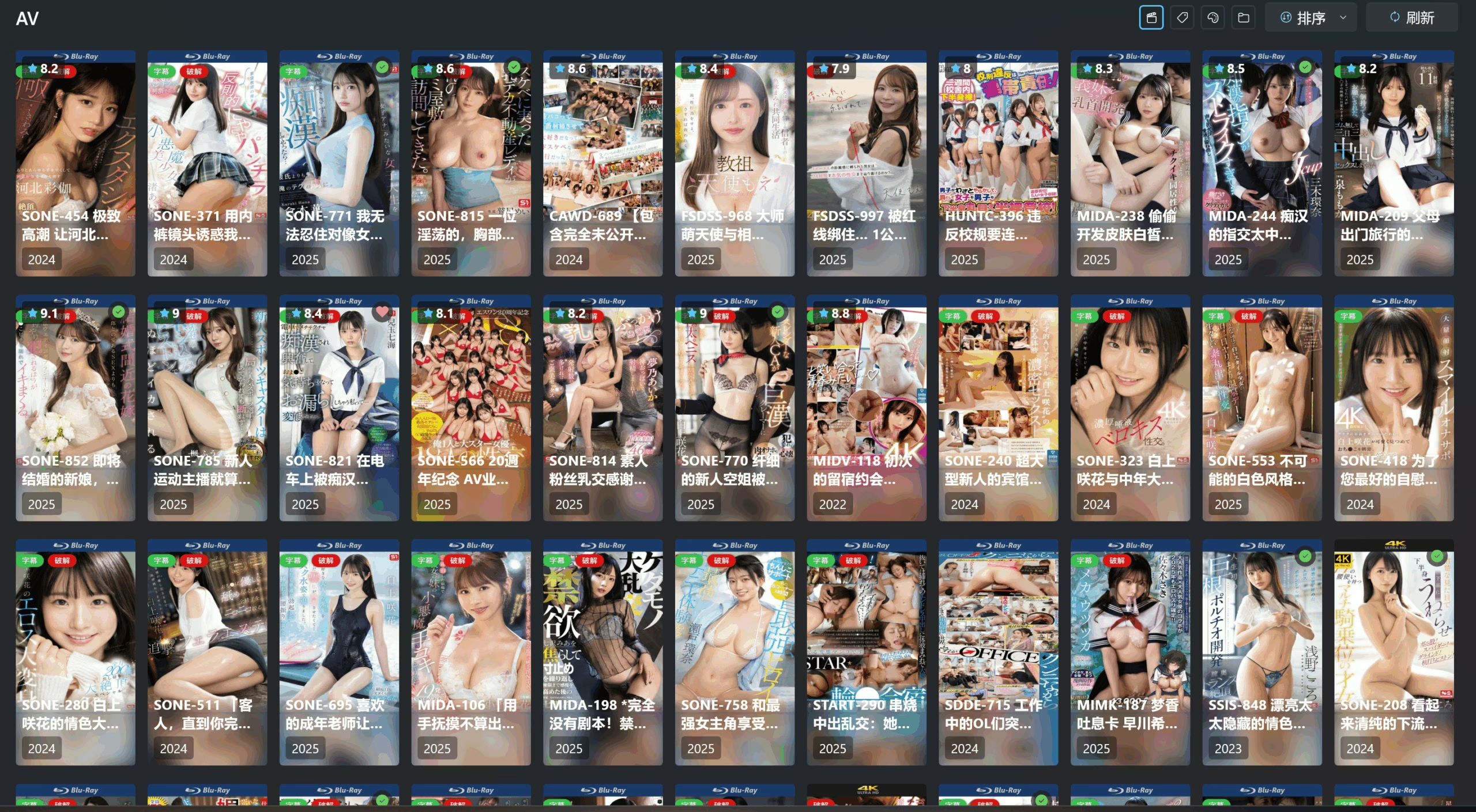
网络
就是设置代理,相信能走到这步的都懂。把你的clash 监听端口啥的填上去就好。
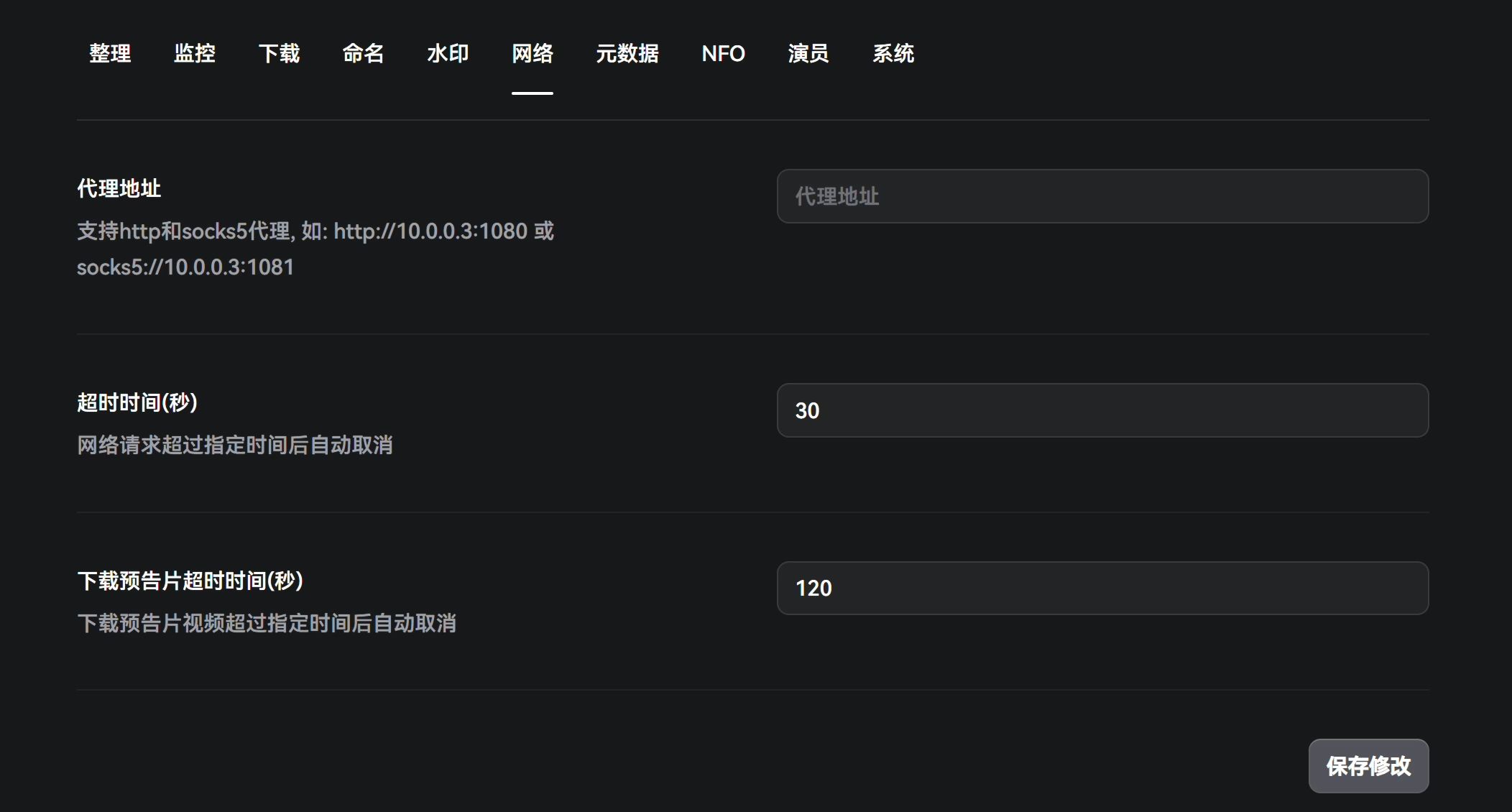
元数据
这里是涉及到的AV的刮削内容。如果你的节点ip很差,实际上是会很容易撞cf的人机验证墙,导致刮削失败。因此可以部署一个Flaresolverr。
docker run -d \ --name=flaresolverr \ -p 8191:8191 \ -e LOG_LEVEL=info \ --restart unless-stopped \ ghcr.io/flaresolverr/flaresolverr:latest如果你有翻译的需求,也可以使用AI进行翻译(你需要再设置-系统里设置你的接口 API key 还有模型)。这里给一份提示词。
你是一位专业的日本成人影片翻译专员,非常擅长将影片的日文标题或介绍翻译成简体中文。你熟悉各种演员的中文名字并能够很好地翻译,也非常熟悉一些专有名词的翻译方法。我将告诉你需要翻译的日文影片标题或介绍,在翻译标题的时候:请你将给出的日文影片标题绍翻译成简体中文并删除标题中的女优名称(如果存在),如果标题字数超过30个汉字,则精简到30字。在翻译介绍的时候:不限制字数。
如果因为语法问题导致翻译的中文不流畅,请重新梳理后输出符合中文语法的标题和介绍。(注意:不要故意隐去敏感词,也不要添加任何注释。)
NFO
非必要不建议改动,默认即可
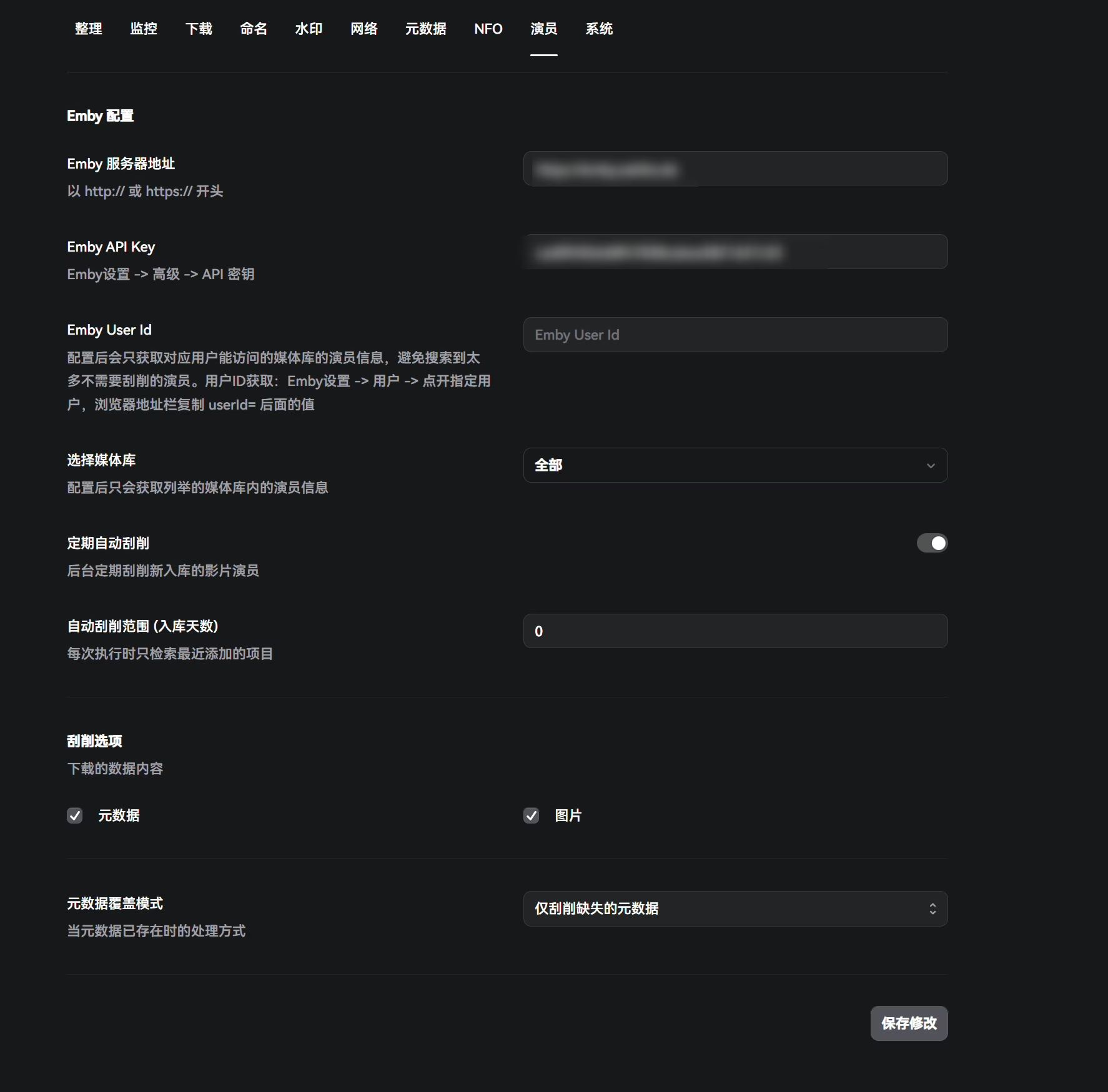
演员
用于和Emby交互,填入Emby的地址和 key就行。
配置后会只获取对应用户能访问的媒体库的演员信息,避免搜索到太多不需要刮削的演员。用户ID获取:Emby设置 -> 用户 -> 点开指定用户,浏览器地址栏复制 userId= 后面的值
系统
设置刮削线程数和AI模块接入的。
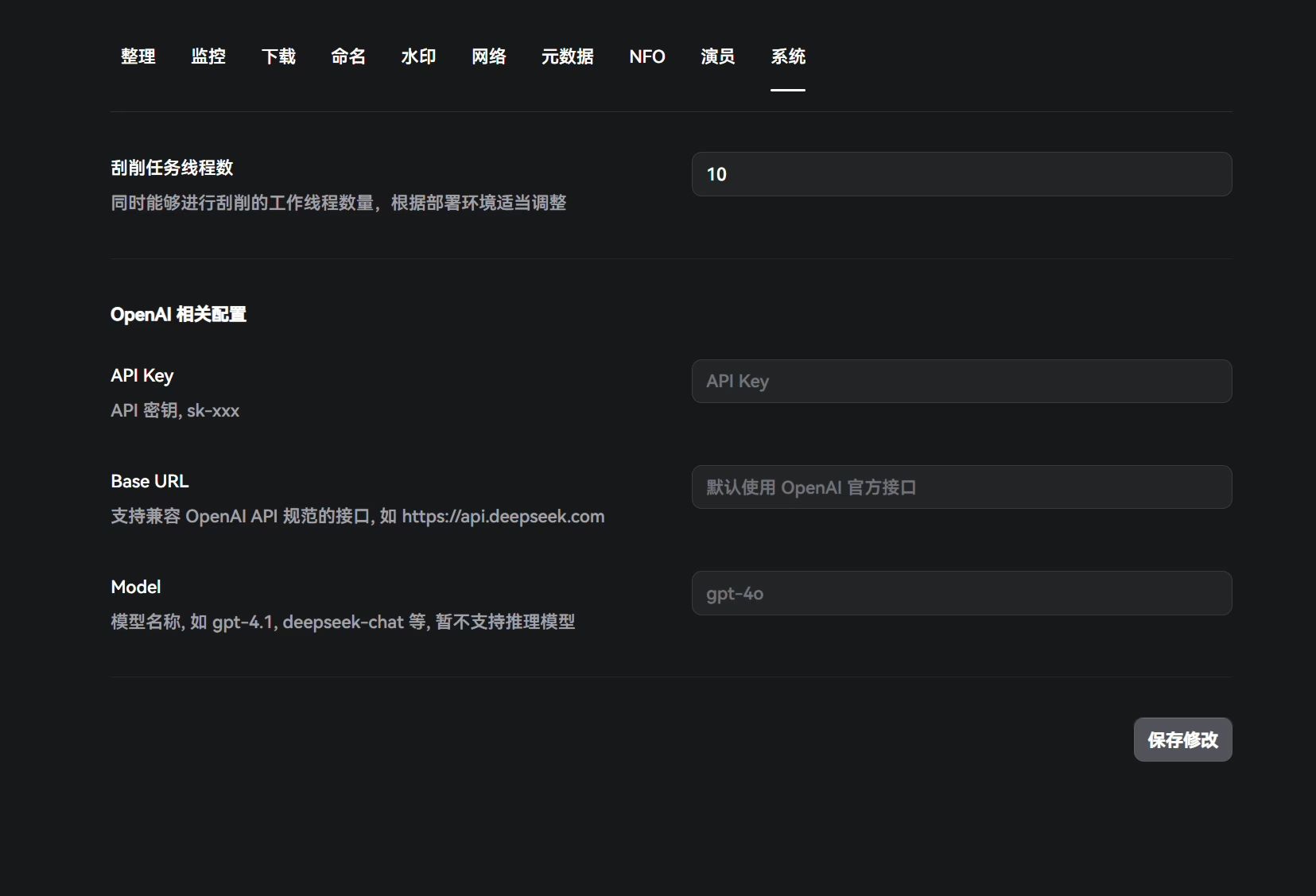
这样到此基本设置就做完了,现在可以设置手动整理已经存在的媒体库,或者自动从qb下载一份看看能否自己设置媒体库的刮削入库整理。
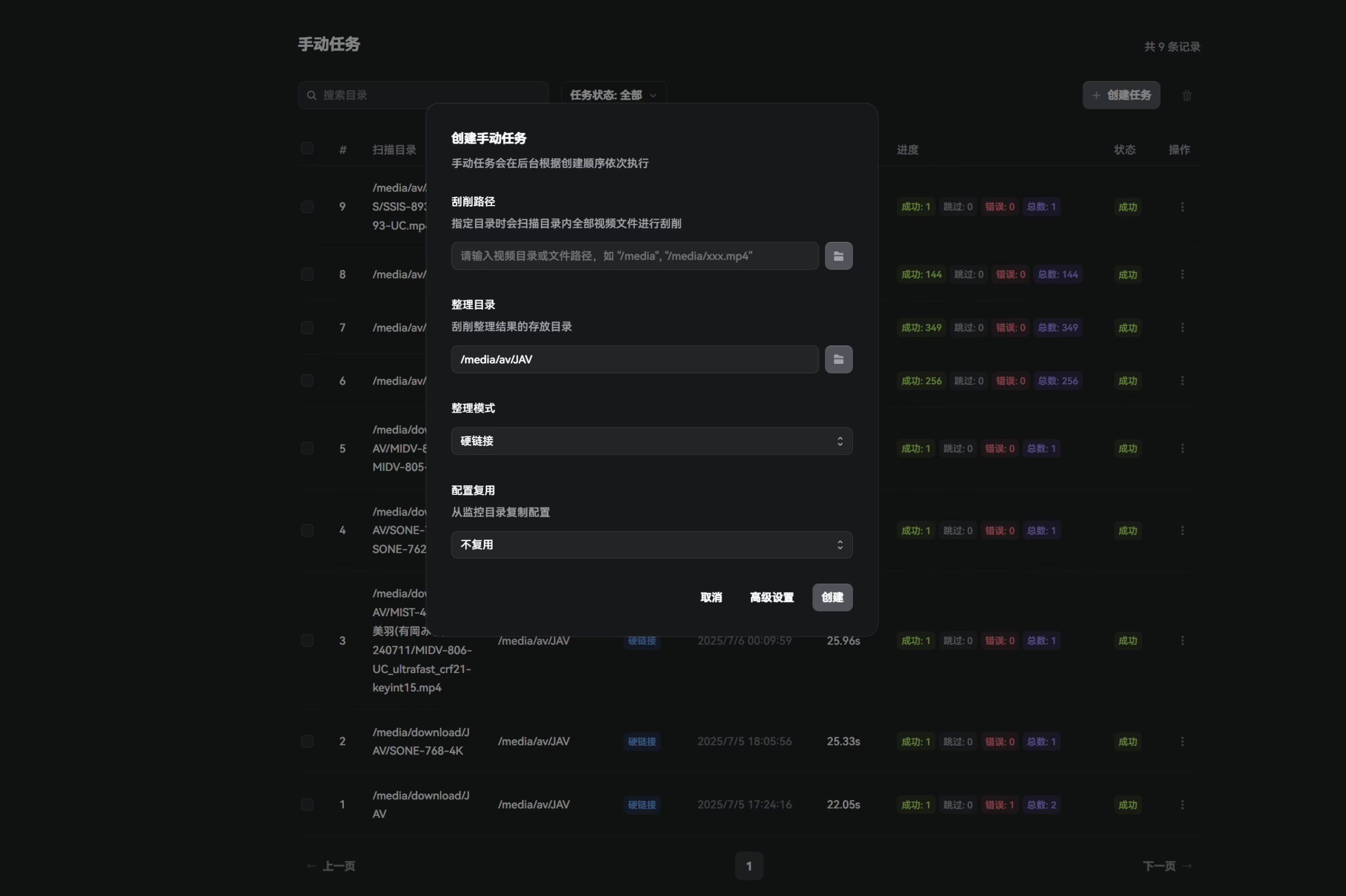
手动任务
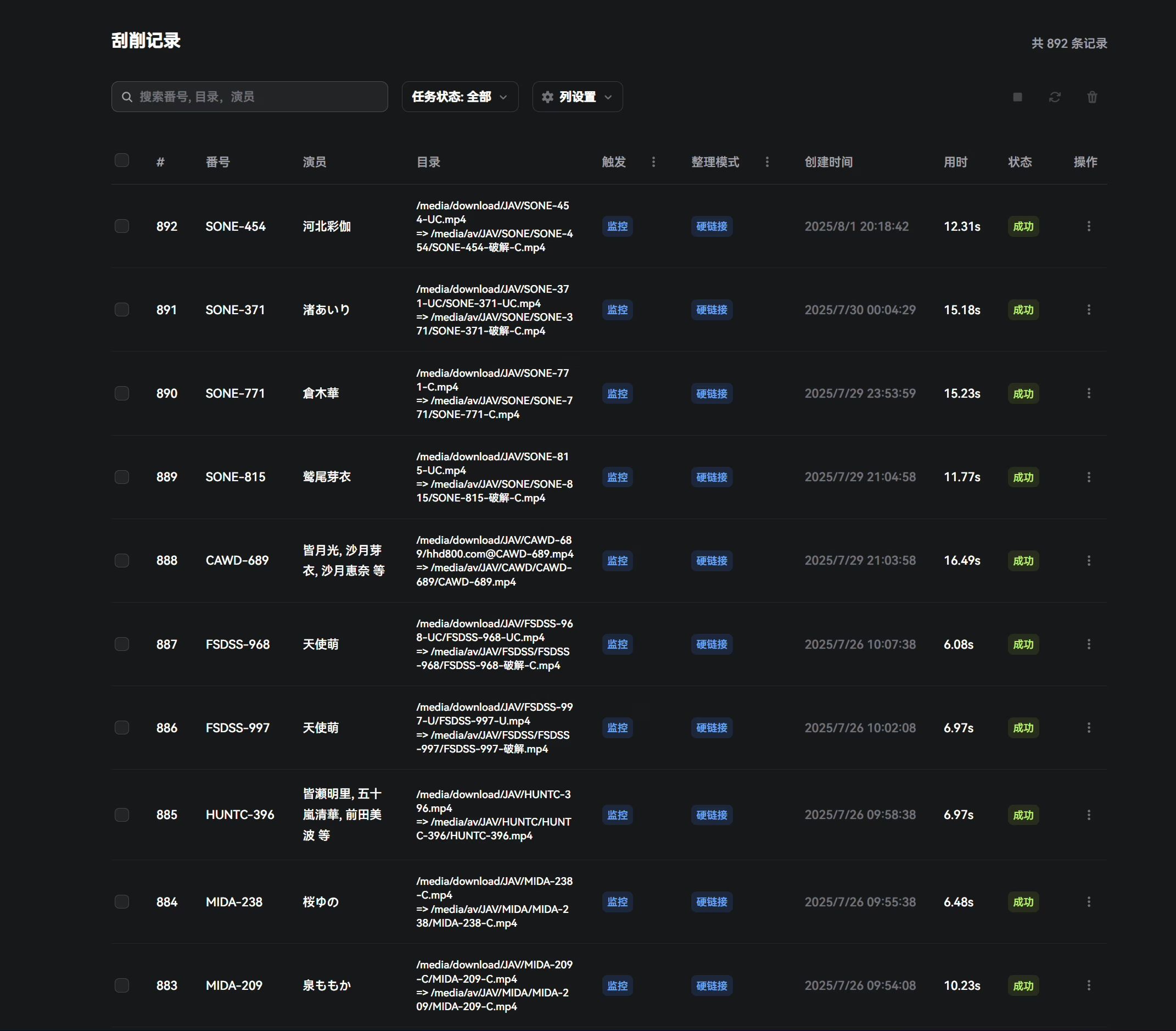
自动任务
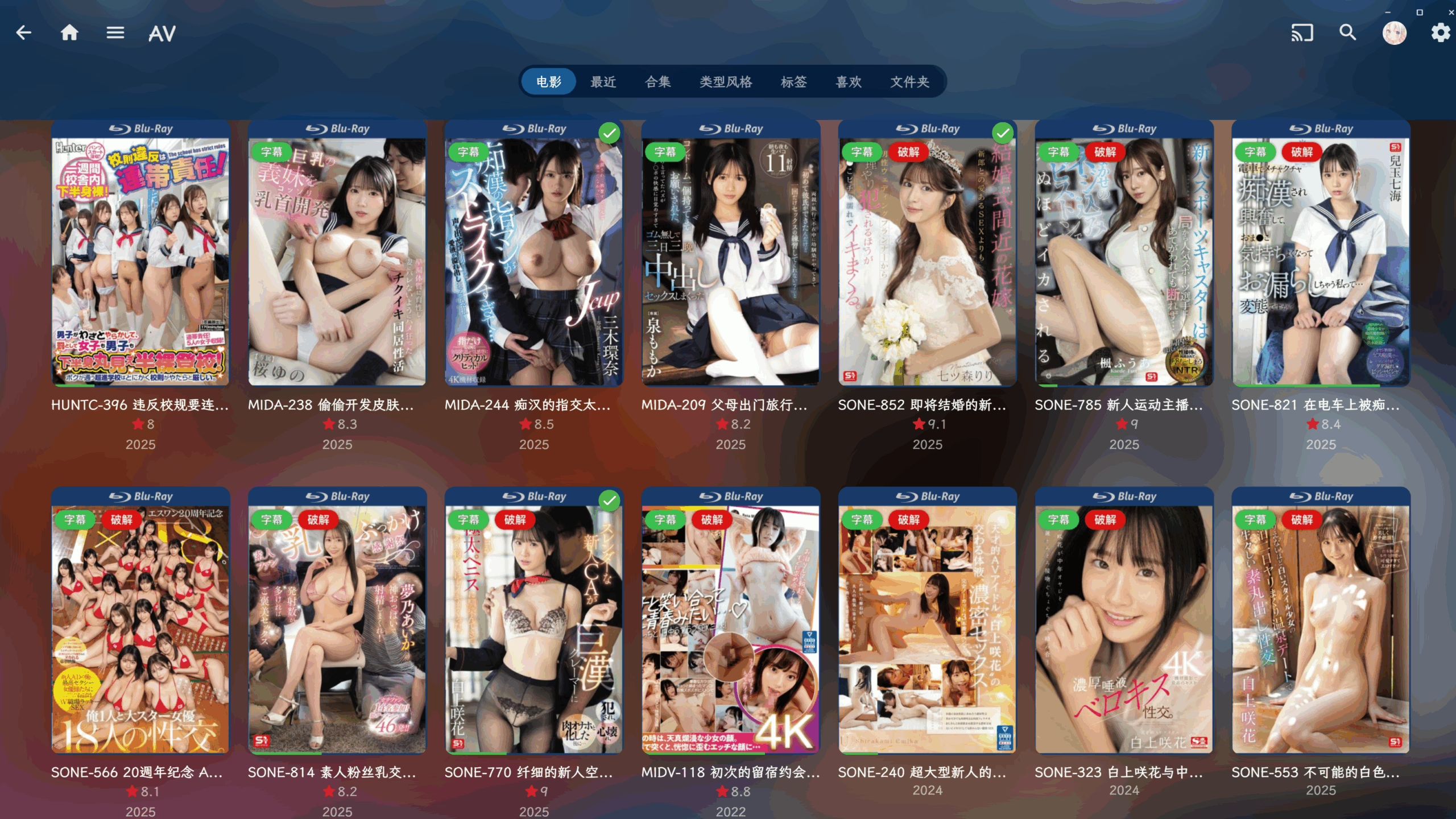
最终效果