
Docker 部署 Scrutiny 监控你的硬盘
在日常使用 NAS、服务器或家用硬盘阵列时,硬盘作为存储的核心,往往是最容易被忽视但最关键的部分。平时运行一切正常,但一块硬盘挂掉时,代价往往是痛的:数据丢失、服务中断、甚至心态崩了。
SMART 是大多数硬盘内建的自我监控技术,但它的原始输出往往杂乱、晦涩、不直观。Scrutiny 是一个轻量、现代化的硬盘监控面板,能通过 SMART 数据直观展示硬盘健康状态、寿命趋势和异常预警,并支持邮件或 Webhook 报警。
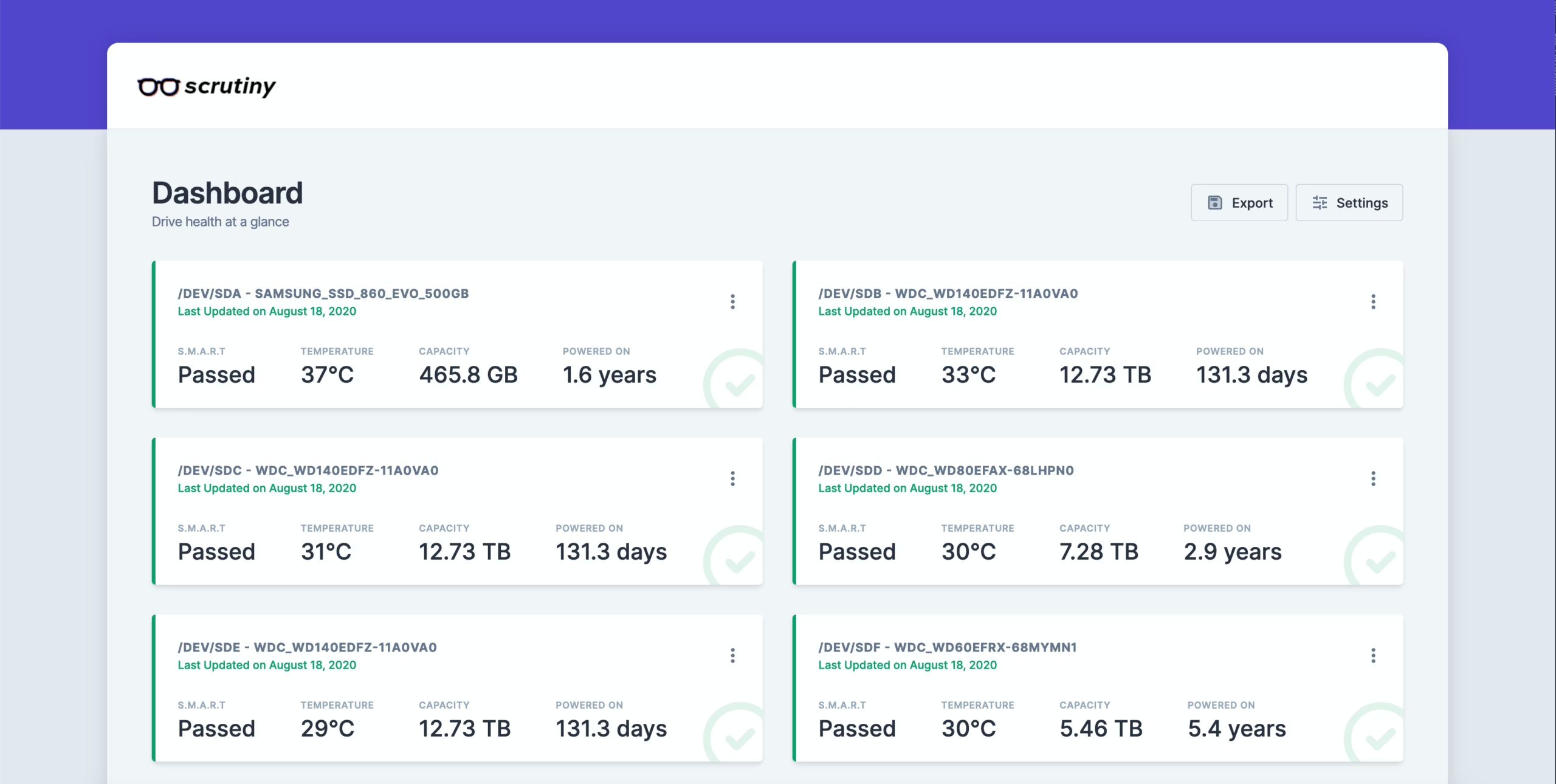
特点
Scrutiny 是一款简单但专注的应用程序,具有以下几个核心功能:
-
Web UI 仪表板 - 专注于关键指标
-
smartd集成 -
自动检测所有连接的硬盘
-
SMART 指标跟踪历史趋势
-
使用真实世界故障率定制阈值
-
温度追踪
-
以一体化 Docker 镜像形式提供(但可以手动安装)
-
通过 Webhook 配置警报/通知
-
(未来)硬盘性能测试和跟踪
部署
创建文件夹
请自己找寻合适的位置mkdir Scrutinydocker-compose.yaml
这里要根据你的实际情况的硬盘名称填,不知道的 lsblk 看一下
如果你想在 Docker 中设置监控的频率,可以添加 COLLECTOR_CRON_SCHEDULE 这个环境变量,例如设置每 15 分钟监控一次就是 -e COLLECTOR_CRON_SCHEDULE="*/15 * * * *" ,这个变量使用的是 Cron 表达式
version: '3.5'
services: scrutiny: container_name: scrutiny image: ghcr.io/analogj/scrutiny:master-omnibus cap_add: - SYS_RAWIO # 获取机械硬盘的S.M.A.R.T 信息,默认即可 - SYS_ADMIN # 获取NVMe硬盘的S.M.A.R.T 信息,没有可以删除 ports: - "8183:8080" # webapp - "8184:8086" # influxDB admin(可以不映射) volumes: - /run/udev:/run/udev:ro - ./config:/opt/scrutiny/config - ./influxdb:/opt/scrutiny/influxdb devices: - "/dev/sda" - "/dev/sdb" - "/dev/sdc" - "/dev/sdd"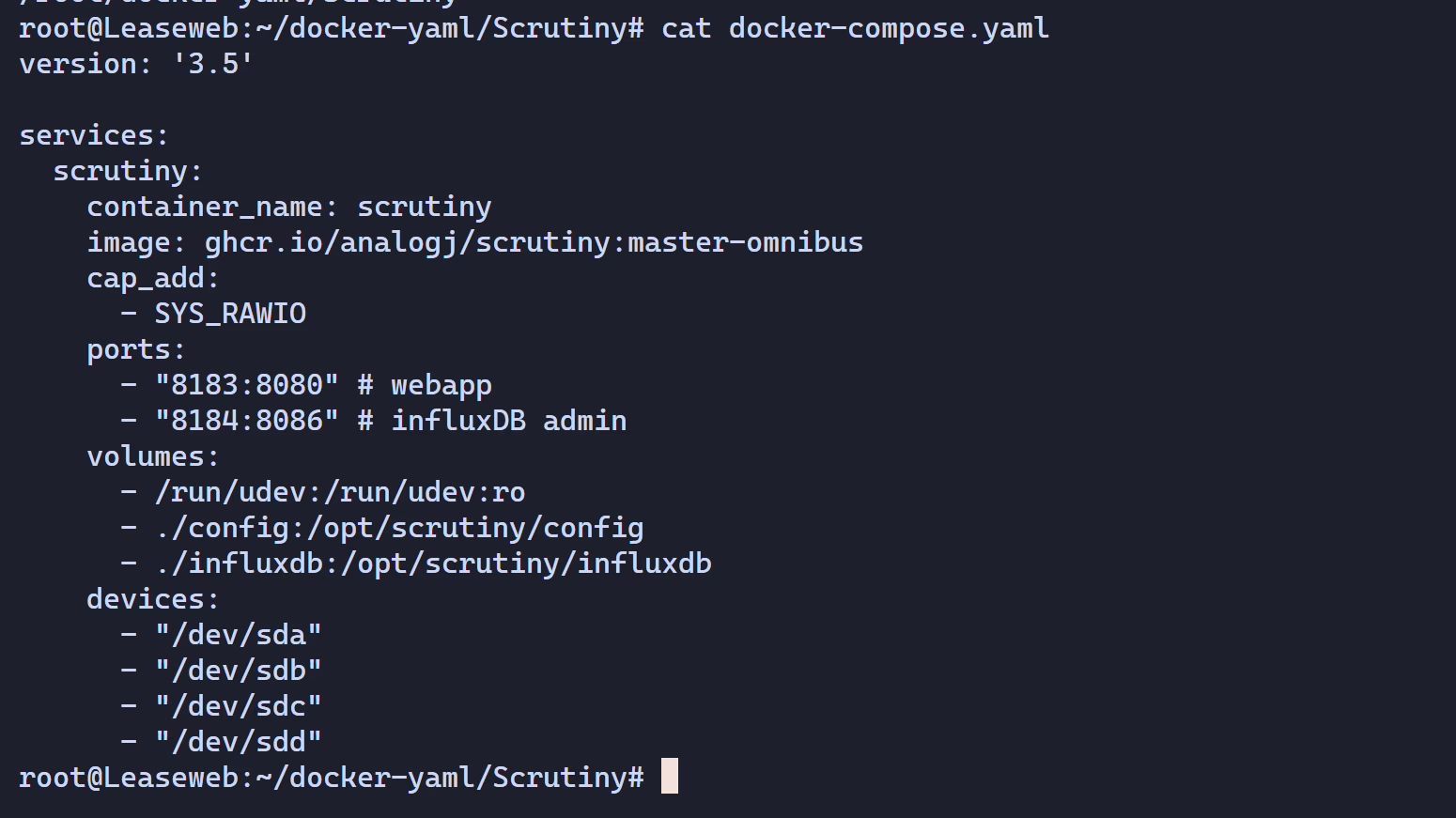
创建启动
docker compose up -d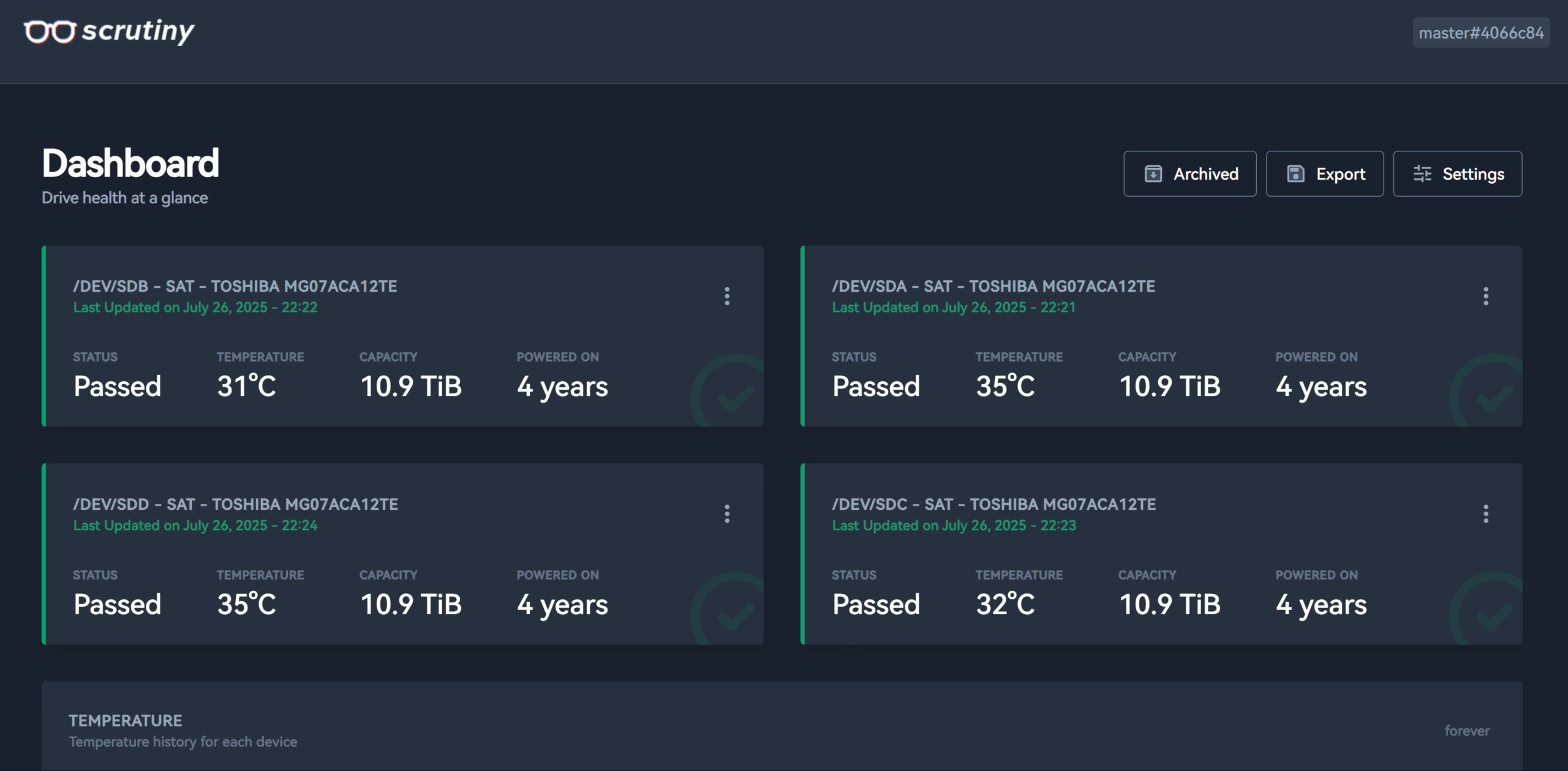
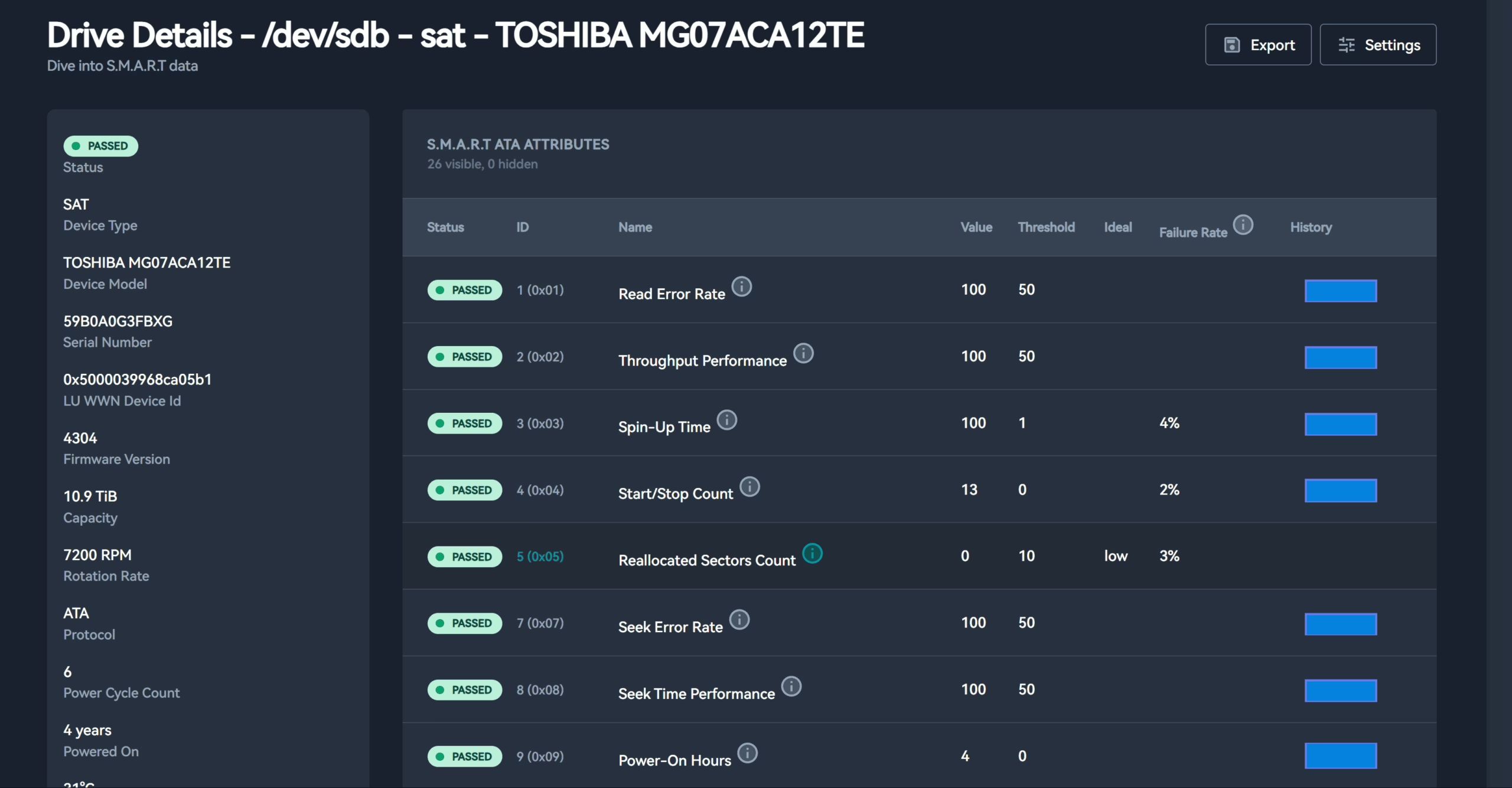
设置通知
仅需要在 $PWD/scrutiny ,下新建一个 scrutiny.yaml 文件,并填入以下内容
notify: urls: - "telegram://token@telegram?channels=channel-1[,channel-2,...]"更详细的通知配置可以查看 https://github.com/AnalogJ/scrutiny#notifications
支持的通知种类和方式都有很多,可以根据自己硬盘情况调整

总结
虽然 SMART 数据本身易于访问,几乎所有现代硬盘和固态硬盘都支持它,但在实际使用中却并不友好。你可以通过命令行工具(比如 smartctl)查看每块磁盘的健康状态、温度、坏道计数、通电时间等信息——但当系统中接入了多块硬盘,甚至是多台主机时,管理这些数据就变得相当繁琐。
每次都得登录对应主机、手动执行命令、复制输出,再去比对、分析是否有异常,这种模式不仅低效,还极易出错。特别是在你真正需要这些数据的时候——比如硬盘开始报错、系统变卡、RAID 突然 degraded,那时再去临时检查,就有点亡羊补牢的感觉了。
Scrutiny 的优势就在于此。它可以定时收集各块硬盘的 SMART 数据,聚合并展示在一个现代化、图形化的 Web 面板中,还支持跨平台运行、多种通知方式(Email、Slack、Telegram、Webhook 等),让你真正做到“硬盘异常,提前预警”。原本只能通过命令行逐一排查的工作,如今一眼便知——不仅效率大幅提升,可读性也达到了另一个层级。